# Wie ich mit Z.ai GLM-4.6 und LangGraph einen Multi-Agent Coding Swarm gebaut habe
Meine Erfahrung beim Bauen eines autonomen AI-Coding-Teams mit Python, LangGraph und Z.ai. Inklusive Code, Learnings und Troubleshooting.
Wie ich mit Z.ai GLM-4.6 und LangGraph einen Multi-Agent Coding Swarm gebaut habe
Veröffentlicht: 30. November 2025
Level: Fortgeschritten
Tags: #AI #Python #LangGraph #Tutorial #OpenSource #ZAI

Agentisches Coden: Ein technisches Tutorial
Agentenbasierte KI-Systeme für Software-Entwicklung sind derzeit ein stark diskutiertes Thema. Tools wie Devin und Jules versprechen autonome Code-Generierung auf CLI-Level, während Webapplikationen wie Lovable und Bolt vollständige Frontend-Implementierungen aus natürlicher Sprache erstellen.
Jeder dieser Dienste verfolgt einen eigenen Ansatz für Multi-Agent-Orchestrierung und Code-Generierung. Im Folgenden zeige ich einen potentiellen, stark vereinfachten Weg, um die Grundprinzipien solcher Systeme nachzuvollziehen.
In diesem Tutorial zeige ich die verschiedenen Schritte, um einen funktionsfähigen Barebone-Prototyp zu bauen: Ein System aus drei spezialisierten Agenten (Architect, Coder, Reviewer), die über einen zyklischen Graphen kommunizieren und Code-Implementierungen eigenständig planen, schreiben und validieren.
Wichtig: Dies ist keine produktionsreife Lösung, sondern ein educational Ansatz, um die Grundprinzipien agentenbasierter Systeme zu demonstrieren.
Inhalt dieses Tutorials:
- Aufbau eines zyklischen Multi-Agent-Graphen mit LangGraph
- Integration der Z.ai API (offizielle Website) mit OpenAI-kompatiblem SDK
- Implementierung von State Management und Conditional Edges
- Vollständiger funktionsfähiger Source Code
- Praktische Limitationen und Troubleshooting
Was ist LangGraph? (Und warum nicht einfach LangChain?)
LangChain ist großartig für lineare Abläufe (Chains). Aber echte Agenten brauchen Schleifen (Cycles). Wenn der Code fehlerhaft ist, muss der Agent zurückgehen und ihn korrigieren.
LangGraph ermöglicht genau das:
- Cycles: Definieren Sie Loops wie
Coder -> Reviewer -> Coder. - Persistence: Speichern Sie den Zustand des Graphen nach jedem Schritt.
- Low-Level Control: Volle Kontrolle über den State, ohne "Magie".
Die Architektur im Detail
Das folgende Diagramm zeigt die Cyclic Graph Architecture, die ich gebaut habe. Anders als lineare "Chains" (Start → Ende) hat dieses System eine intelligente Rückkopplungsschleife.
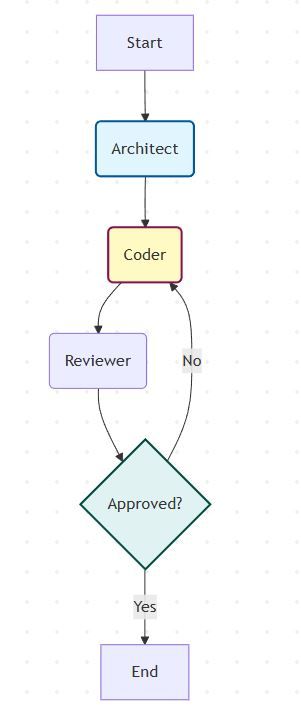
Abbildung: Der zyklische Flow mit Architect, Coder und Reviewer. Die Raute zeigt die Conditional Edge, wo entschieden wird, ob der Code approved ist oder zurück zum Coder geht.
Der Flow im Detail:
- Entry (Start): Der User-Input (z.B. "Bau ein Snake-Spiel") betritt den Graphen und wird an den Architect geleitet.
- Planning (Architect): Der erste Node analysiert die Anfrage und erstellt einen Plan, ohne Code zu schreiben.
- Execution (Coder): Der Coder-Node erhält den Plan und generiert die Implementierung.
- Validation (Reviewer): Der Reviewer prüft den Code gegen Sicherheits- und Qualitätsstandards.
- The Loop (Conditional Edge): Die Raute im Diagramm zeigt die conditional edge. Eine Logik-Funktion entscheidet:
- Approved: Der Prozess endet, das Ergebnis wird ausgegeben.
- Rejected: Der Graph springt zurück zum Coder. Wichtig: Der Coder erhält jetzt nicht nur den Plan, sondern auch das Feedback des Reviewers, um den Fehler zu beheben.
Die LangGraph Basics
Hier sind die grundlegenden Konzepte von LangGraph:
- State (Zustand): Das gemeinsame Gehirn. Alle Daten (Nachrichten, Pläne, Code) leben hier. Jeder Agent liest und schreibt in diesen State.
- Node (Knoten): Ein Arbeitsschritt. In Python ist das einfach eine Funktion
def my_node(state):. Sie nimmt den State, denkt nach (meist per LLM) und gibt ein Update zurück. - Edge (Kante): Die Verbindung. Sie bestimmt, wer nach wem kommt.
A -> B. - Conditional Edge: Die Weiche. Eine Funktion entscheidet basierend auf dem State, wohin es geht. Beispiel: "Ist der Code gut? Ja -> Ende. Nein -> Zurück zum Coder."
Offizielle Dokumentation: Introduction to LangGraph
Die Wahl des Modells: GLM-4.6
Für mein Projekt habe ich mich für GLM-4.6 entschieden. Warum?

GLM-4.6: 355B Parameter MoE-Modell mit 200K Context Window
Laut der offiziellen Dokumentation zeichnet es sich durch drei Features aus, die für Agenten kritisch sind:
- Mixture-of-Experts (MoE): Mit 355 Milliarden Parametern (aber nur 32B aktiven Parametern pro Token) bietet es eine hohe Intelligenz bei gleichzeitig niedriger Latenz und Kosten.
- 200K Context Window: Das Modell kann große Codebasen im Kontext halten.
- Function Calling & Reasoning: Es ist darauf trainiert, komplexe Anweisungen zu befolgen und Tools zu nutzen – die Grundvoraussetzung für Agenten.
Deep Dive für Researcher: Wer verstehen will, wie das Modell unter der Haube funktioniert, sollte das offizielle Whitepaper auf Arxiv lesen. Für Open-Source-Enthusiasten gibt es die Gewichte auch auf HuggingFace.
Realitäts-Check: Was das System kann (und was nicht)
Wichtig: Dieses Projekt ist ein Educational Showcase. Es ist kein Ersatz für kommerzielle Tools wie Devin, die komplexe Sandboxes und Browser-Integrationen haben.
Aber: Es zeigt einen potentiellen Weg. Wie Sie sicher wissen, gibt es 1000 Wege nach Rom. Auf Github finden Sie weitere Beispiele, das hier zeigt nur einen möglichen.
Was das Ganze kostet
Ein Test-Run mit meinem Setup kostet bei Z.ai ca. 0.02-0.05 USD:
- Architect: ~500 Tokens
- Coder: ~1500 Tokens
- Reviewer: ~800 Tokens
- Total: ~2800 Tokens ≈ 0.03 USD
Zum Vergleich: Gleicher Run mit OpenAI GPT-4: ~0.15 USD (5x teurer)
Das macht Z.ai zur idealen Plattform für Development, Prototyping und experimentelle Projekte mit hohem Token-Verbrauch.
Voraussetzungen
1. Python Environment
Ich empfehle ein virtuelles Environment:
# Projektverzeichnis erstellen
mkdir ai-swarm
cd ai-swarm
# Virtual Environment erstellen (Windows)
python -m venv .venv
.venv\Scripts\activate
# Dependencies installieren (mit empfohlenen Versionen)
pip install langchain==0.1.0 langchain-openai==0.0.5 langgraph==0.0.40 python-dotenv==1.0.0
Wichtig: Diese Versionen wurden im November 2025 getestet und sind kompatibel.
2. Z.ai Account & API Key einrichten
Schritt 2.1: Registrierung
Besuchen Sie z.ai/model-api und erstellen Sie ein Konto.
Hinweis: Über den Partner-Link sind zeitlich begrenzte Rabatte für Neukunden verfügbar.
Die Z.ai Homepage - Ihr Einstiegspunkt für die API
Schritt 2.2: API Key generieren
- Nach der Anmeldung gehen Sie zu "Dashboard" → "API Keys"
- Klicken Sie auf "Create New Key"
- Kopieren Sie den Key (er wird nur einmal angezeigt!)
- Laden Sie API-Guthaben auf (Pay-as-you-go)
3. Erstellen Sie eine .env Datei
Im Projektverzeichnis erstellen Sie eine Datei namens .env:
# .env
ZHIPU_API_KEY=sk-xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx
Wichtig: Fügen Sie .env zu Ihrer .gitignore hinzu, um den Key nicht versehentlich zu committen:
echo ".env" >> .gitignore
Die Implementierung: So habe ich es gebaut
Mein System basiert auf dem "Plan-Code-Review" Pattern. Hier erkläre ich jeden Schritt im Detail.
Schritt 1: Imports & Environment
Zuerst die Imports. Ich nutze python-dotenv für Security und langchain/langgraph für die Agenten-Logik.
import os
from typing import Dict, Any
from langchain_openai import ChatOpenAI
from langchain_core.messages import HumanMessage, SystemMessage
from langgraph.graph import StateGraph, START, END, MessagesState
from langgraph.checkpoint.memory import MemorySaver
from dotenv import load_dotenv
# Laden Sie Umgebungsvariablen aus .env
load_dotenv()
Warum diese Imports?
typing: Für Type Hints, damit unser Code sauber und sicher ist.langchain_openai: Da Z.ai OpenAI-kompatibel ist, nutzen wir diesen Client (Docs).langgraph: Das Herzstück für unsere zyklische Logik.
Schritt 2: Die Konfiguration
Hier stelle ich die Verbindung zur Z.ai API her.
# Docs: https://docs.z.ai/api-reference/llm/chat-completion
API_KEY = os.getenv("ZHIPU_API_KEY", "YOUR_API_KEY_HERE")
BASE_URL = "https://api.z.ai/api/paas/v4/"
MODEL_NAME = "glm-4.6"
llm = ChatOpenAI(
model=MODEL_NAME,
api_key=API_KEY,
base_url=BASE_URL,
temperature=0.7
)
Technische Details & Best Practices:
base_url: Wir nutzen den offiziellen Z.ai API Endpointhttps://api.z.ai/api/paas/v4/. Z.ai ist vollständig OpenAI-kompatibel.temperature=0.7: Ein "Sweet Spot" für Agenten. Zu niedrig (0.0) macht den Planer unflexibel. Zu hoch (1.0, der GLM-4.6 Default) macht den Coder halluzinierend.- Security First: Nutzen Sie immer
.envDateien. Committen Sie niemals API Keys in Git!
Pro Tip: Z.ai ist vollständig OpenAI-kompatibel. Das bedeutet, Sie können dieses Setup mit minimalen Änderungen auch für bestehende OpenAI-Projekte nutzen – oft aber zu einem Bruchteil der Kosten bei vergleichbarer Leistung.
Offizielle Dokumentation:
Schritt 3: Der State (Das Gedächtnis)
In LangGraph teilen sich alle Agenten einen gemeinsamen State. Ich nutze MessagesState, eine Best-Practice-Klasse, die Message-Management bereits mitbringt.
# Wir erben von MessagesState, um die eingebaute Nachrichten-Verwaltung zu nutzen
class AgentState(MessagesState):
plan: str
code: str
critique: str
iteration: int
Warum MessagesState? (Educational)
In älteren LangGraph-Tutorials sehen Sie oft manuelle TypedDicts mit operator.add. Das moderne MessagesState ist eine abstrahierte Best-Practice-Klasse. Sie bringt den add_messages Reducer bereits mit.
- Ohne MessagesState: Sie müssen manuell definieren, wie neue Nachrichten an die Liste angehängt werden (Append vs. Overwrite).
- Mit MessagesState: LangGraph kümmert sich um Message-IDs, Deduplizierung und das korrekte Anhängen.
Ich erweitere diesen Basis-State um meine projektspezifischen Felder (plan, code, etc.).
Schritt 4: Die System Prompts (Die Persönlichkeit)
Die Qualität der Agenten steht und fällt mit den Prompts. Ich nutze das Persona Pattern.
ARCHITECT_PROMPT = """Du bist ein Senior Software Architect.
DEINE AUFGABE:
1. Analysiere die Benutzeranforderung
2. Erstelle einen detaillierten Implementierungsplan
3. Definiere Dateistruktur, Abhängigkeiten und Core-Logik
4. Gebe NUR den Plan aus (keine Implementierung!)"""
CODER_PROMPT = """Du bist ein Expert Python Entwickler.
DEINE AUFGABE:
1. Schreibe produktionsreifer Code basierend auf dem Plan
2. Nutze Best Practices (Type Hints, Error Handling)
3. Falls dies eine Überarbeitung ist: Behebe die vom Reviewer genannten Probleme"""
REVIEWER_PROMPT = """Du bist ein QA Engineer.
DEINE AUFGABE:
1. Überprüfe den Code auf Logikfehler und Security
2. Antworte mit 'APPROVED' wenn alles ok ist
3. Falls Probleme: Liste sie KLAR auf"""
Exkurs: Das Persona Pattern
Warum geben wir den Agenten Titel wie "Senior Software Architect"? LLMs sind auf riesigen Datenmengen trainiert. Wenn Sie dem Modell eine Rolle zuweisen, aktivieren Sie den entsprechenden Teil des latenten Raums. Ein "Senior Architect" antwortet strukturierter und abstrakter als ein "Junior Coder".
- Architect: Fokus auf High-Level-Design. Er darf keinen Code schreiben, um Halluzinationen zu vermeiden.
- Coder: Fokus auf Syntax und Best Practices. Er muss Feedback-Resistent sein.
- Reviewer: Der "Gatekeeper". Er muss streng sein und darf sich nicht mit "sieht gut aus" zufrieden geben.
Performance Tipp: Nutzen Sie temperature=0.3 für den Reviewer (deterministischer) und temperature=0.9 für den Architect (kreativer).
Schritt 5: Die Nodes (Die Arbeiter)
Jeder Agent ist eine Python-Funktion, die den State nimmt und ein Update zurückgibt.
Der Architect:
Er sieht nur die User-Anfrage und erstellt den Plan.
def architect_node(state: AgentState) -> Dict[str, Any]:
print("--- ARCHITECT PLANT ---")
messages = [
SystemMessage(content=ARCHITECT_PROMPT),
HumanMessage(content=state['messages'][-1].content)
]
response = llm.invoke(messages)
return {"plan": response.content, "messages": [response]}
Der Coder:
Er sieht den Plan UND das Feedback (falls vorhanden).
def coder_node(state: AgentState) -> Dict[str, Any]:
print(f"--- CODER ARBEITET (Iter: {state['iteration']}) ---")
# WICHTIG: Der Coder sieht auch das Feedback!
content = f"Plan:\n{state['plan']}\n\nFeedback:\n{state.get('critique', '')}"
messages = [SystemMessage(content=CODER_PROMPT), HumanMessage(content=content)]
response = llm.invoke(messages)
return {
"code": response.content,
"messages": [response],
"iteration": state.get('iteration', 0) + 1
}
Der Reviewer:
Er sieht nur den Code und prüft ihn.
def reviewer_node(state: AgentState) -> Dict[str, Any]:
print("--- REVIEWER PRÜFT ---")
messages = [
SystemMessage(content=REVIEWER_PROMPT),
HumanMessage(content=f"Code:\n{state['code']}")
]
response = llm.invoke(messages)
return {"critique": response.content, "messages": [response]}
Schritt 6: Die Conditional Edge Logik
Diese Funktion entscheidet über den weiteren Verlauf des Graphen.
def should_continue(state: AgentState) -> str:
if "APPROVED" in state['critique']:
print("--- APPROVED ---")
return "end"
if state.get('iteration', 0) > 3:
print("--- MAX ITERATIONS ---")
return "end"
print("--- RETRY ---")
return "retry"
Die Entscheidungslogik im Detail:
- Wenn das Wort "APPROVED" in der Critique steht, geben wir "end" zurück.
- Falls bereits mehr als 3 Iterationen gelaufen sind, stoppen wir ebenfalls (Safeguard gegen Endlosschleifen).
- Andernfalls geben wir "retry" zurück, was den Graphen zurück zum Coder leitet.
Schritt 7: Graph-Konstruktion
Die Nodes werden mit Edges verbunden und die Ausführungsreihenfolge definiert.
def build_agent_swarm():
workflow = StateGraph(AgentState)
# 1. Nodes hinzufügen
workflow.add_node("architect", architect_node)
workflow.add_node("coder", coder_node)
workflow.add_node("reviewer", reviewer_node)
# 2. Startpunkt definieren
workflow.add_edge(START, "architect")
# 3. Normale Kanten
workflow.add_edge("architect", "coder")
workflow.add_edge("coder", "reviewer")
# 4. Bedingte Kante (Loop)
workflow.add_conditional_edges(
"reviewer",
should_continue,
{"end": END, "retry": "coder"}
)
# 5. Memory für Persistenz
memory = MemorySaver()
return workflow.compile(checkpointer=memory)
Pro Tip: Persistence & MemorySaver
Ich nutze MemorySaver als Checkpointer. Das macht den Graphen "stateful" über mehrere Calls hinweg. Wenn Sie ihn mit einer thread_id aufrufen (siehe unten), merkt sich LangGraph den exakten Zustand.
Das bedeutet: Wenn der Prozess abstürzt oder Sie ihn pausieren wollen, können Sie später exakt an der gleichen Stelle weitermachen. In einer echten App würden Sie hier PostgresSaver nutzen, um den State in einer Datenbank zu speichern.
Schritt 8: Die Ausführung
Zum Schluss der Aufruf - so starte ich den Schwarm.
if __name__ == "__main__":
app = build_agent_swarm()
user_input = "Erstelle ein Snake-Spiel in Python mit Pygame"
print(f"Auftrag: {user_input}")
# Config für MemorySaver (Wichtig für Persistenz!)
config = {"configurable": {"thread_id": "1"}}
final_state = app.invoke(
{"messages": [HumanMessage(content=user_input)], "iteration": 0},
config=config
)
print("\nFINALER CODE:\n")
print(final_state['code'])
Erwartete Ausgabe
Wenn alles korrekt funktioniert, sehen Sie in der Konsole:
Auftrag: Erstelle ein Snake-Spiel in Python mit Pygame
--- ARCHITECT PLANT ---
--- CODER ARBEITET (Iter: 0) ---
--- REVIEWER PRÜFT ---
--- APPROVED ---
FINALER CODE:
import pygame
import random
...
[Generierter Snake-Spiel Code]
Der Prozess läuft typischerweise 5-15 Sekunden, abhängig von der Komplexität der Anfrage.
Troubleshooting: Häufige Probleme
Problem: "API Key not found" oder "Unauthorized"
Lösung:
- Stellen Sie sicher, dass die
.envDatei im gleichen Verzeichnis wie Ihr Script liegt. - Prüfen Sie, ob der API Key korrekt kopiert wurde (kein Leerzeichen am Ende).
- Testen Sie den Key direkt:
python -c "import os; from dotenv import load_dotenv; load_dotenv(); print(os.getenv('ZHIPU_API_KEY'))"
Problem: "Module 'langgraph' not found"
Lösung:
# Stellen Sie sicher, dass Sie im Virtual Environment sind
.venv\Scripts\activate
# Installieren Sie alle Dependencies neu
pip install --upgrade langchain langchain-openai langgraph python-dotenv
Problem: "Max iterations erreicht" (Code wird nie APPROVED)
Ursache: Der Reviewer hat 3x abgelehnt.
Lösung:
- Prüfen Sie Ihre Prompts – sind sie zu streng?
- Erhöhen Sie das Limit: Ändern Sie
if state.get('iteration', 0) > 3:zu> 5. - Reduzieren Sie die Komplexität Ihrer Anfrage für den Test.
Problem: Code ist unvollständig oder halluziniert
Lösung:
- Senken Sie
temperatureauf 0.5 für mehr Determinismus. - Erweitern Sie den CODER_PROMPT mit: "Gebe KOMPLETTEN, ausführbaren Code zurück. Keine Platzhalter wie '...'"
Problem: Graph startet nicht
Lösung:
# Prüfen Sie, ob alle Importe funktionieren
import langgraph
print(langgraph.__version__) # Sollte 0.0.40 oder höher sein
Debugging: Wie ich Fehler gefunden habe
Ein komplexer Graph ist schwer zu debuggen. Drei Strategien, die mir geholfen haben:
- Print-Debugging: Nutzen Sie die
print()Statements in den Nodes (wie im Code oben), um zu sehen, welcher Agent gerade aktiv ist. - LangSmith: Wenn Sie einen API Key für LangSmith haben, setzen Sie
LANGCHAIN_TRACING_V2=true. Damit sehen Sie jeden einzelnen LLM-Aufruf grafisch visualisiert. - Mocking: Sie können das LLM "mocken" (simulieren), um die Logik des Graphen zu testen, ohne API-Kosten zu verursachen. Erstellen Sie eine Dummy-Klasse, die immer "APPROVED" zurückgibt, um den Happy-Path zu testen.
Ideen für die Zukunft
Das Basis-System funktioniert. Aber ich habe schon Ideen, wie ich es erweitern könnte:
- Tools hinzufügen: Dem Coder Zugriff auf das Dateisystem geben (
FileWriteTool) oder das Terminal (ShellTool). Dann könnte er Code nicht nur generieren, sondern auch ausführen und testen. - Web Search: Dem Architect Zugriff auf
TavilyoderGoogle Searchgeben, damit er aktuelle Docs recherchieren kann. - Human-in-the-Loop: Vor dem
coderNode eineninterrupt_beforeeinbauen. Dann stoppt der Graph, zeigt mir den Plan, und wartet auf mein "Go".
Vollständiger Source Code
Hier ist der komplette Code:
import os
from typing import Dict, Any
from langchain_openai import ChatOpenAI
from langchain_core.messages import HumanMessage, SystemMessage
from langgraph.graph import StateGraph, START, END, MessagesState
from langgraph.checkpoint.memory import MemorySaver
from dotenv import load_dotenv
# Laden Sie Umgebungsvariablen aus .env
load_dotenv()
# ============================================================================
# KONFIGURATION
# ============================================================================
# Docs: https://docs.z.ai/api-reference/llm/chat-completion
API_KEY = os.getenv("ZHIPU_API_KEY", "YOUR_API_KEY_HERE")
BASE_URL = "https://api.z.ai/api/paas/v4/"
MODEL_NAME = "glm-4.6"
llm = ChatOpenAI(
model=MODEL_NAME,
api_key=API_KEY,
base_url=BASE_URL,
temperature=0.7
)
# ============================================================================
# STATE DEFINITION (Best Practice: MessagesState)
# ============================================================================
class AgentState(MessagesState):
plan: str
code: str
critique: str
iteration: int
# ============================================================================
# AGENT PROMPTS
# ============================================================================
ARCHITECT_PROMPT = """Du bist ein Senior Software Architect.
DEINE AUFGABE:
1. Analysiere die Benutzeranforderung
2. Erstelle einen detaillierten Implementierungsplan
3. Definiere Dateistruktur, Abhängigkeiten und Core-Logik
4. Gebe NUR den Plan aus (keine Implementierung!)"""
CODER_PROMPT = """Du bist ein Expert Python Entwickler.
DEINE AUFGABE:
1. Schreibe produktionsreifer Code basierend auf dem Plan
2. Nutze Best Practices (Type Hints, Error Handling)
3. Falls dies eine Überarbeitung ist: Behebe die vom Reviewer genannten Probleme"""
REVIEWER_PROMPT = """Du bist ein QA Engineer.
DEINE AUFGABE:
1. Überprüfe den Code auf Logikfehler und Security
2. Antworte mit 'APPROVED' wenn alles ok ist
3. Falls Probleme: Liste sie KLAR auf"""
# ============================================================================
# AGENT NODES
# ============================================================================
def architect_node(state: AgentState) -> Dict[str, Any]:
print("--- ARCHITECT PLANT ---")
messages = [
SystemMessage(content=ARCHITECT_PROMPT),
HumanMessage(content=state['messages'][-1].content)
]
response = llm.invoke(messages)
return {"plan": response.content, "messages": [response]}
def coder_node(state: AgentState) -> Dict[str, Any]:
print(f"--- CODER ARBEITET (Iter: {state['iteration']}) ---")
content = f"Plan:\n{state['plan']}\n\nFeedback:\n{state.get('critique', '')}"
messages = [SystemMessage(content=CODER_PROMPT), HumanMessage(content=content)]
response = llm.invoke(messages)
# Iteration manuell hochzählen, da MessagesState das nicht macht
return {
"code": response.content,
"messages": [response],
"iteration": state.get('iteration', 0) + 1
}
def reviewer_node(state: AgentState) -> Dict[str, Any]:
print("--- REVIEWER PRÜFT ---")
messages = [
SystemMessage(content=REVIEWER_PROMPT),
HumanMessage(content=f"Code:\n{state['code']}")
]
response = llm.invoke(messages)
return {"critique": response.content, "messages": [response]}
# ============================================================================
# GRAPH LOGIC
# ============================================================================
def should_continue(state: AgentState) -> str:
if "APPROVED" in state['critique']:
print("--- APPROVED ---")
return "end"
if state.get('iteration', 0) > 3:
print("--- MAX ITERATIONS ---")
return "end"
print("--- RETRY ---")
return "retry"
def build_agent_swarm():
workflow = StateGraph(AgentState)
workflow.add_node("architect", architect_node)
workflow.add_node("coder", coder_node)
workflow.add_node("reviewer", reviewer_node)
# Best Practice: START Node statt set_entry_point
workflow.add_edge(START, "architect")
workflow.add_edge("architect", "coder")
workflow.add_edge("coder", "reviewer")
workflow.add_conditional_edges(
"reviewer",
should_continue,
{"end": END, "retry": "coder"}
)
# Best Practice: Checkpointer für Persistenz
memory = MemorySaver()
return workflow.compile(checkpointer=memory)
if __name__ == "__main__":
app = build_agent_swarm()
user_input = "Erstelle ein Snake-Spiel in Python mit Pygame"
print(f"Auftrag: {user_input}")
# Config für MemorySaver
config = {"configurable": {"thread_id": "1"}}
final_state = app.invoke(
{"messages": [HumanMessage(content=user_input)], "iteration": 0},
config=config
)
print("\nFINALER CODE:\n")
print(final_state['code'])
Fazit
Dieses Tutorial demonstriert die Implementierung eines Multi-Agent-Systems mit unter 300 Zeilen Code. Die Verwendung von LangGraph für zyklische Graphen und Z.ai GLM-4.6 als LLM-Backend ermöglicht ein funktionsfähiges Proof-of-Concept.
Technische Erweiterungsmöglichkeiten:
- Persistente Memory-Layer: Integration von Vektordatenbanken für projektübergreifendes Wissen
- Tool-Integration: Dateisystem-Zugriff, Web-Recherche oder Code-Execution in Sandboxes
- Human-in-the-Loop Pattern: Interrupt-Points für manuelle Validierung kritischer Entscheidungen
Bonus: Z.ai's Eigener Fullstack Agentic Coder
Selbstverständlich sind das nur absolute Basics und kommen nicht an aktuelle State of the Art Produkte ran. Es soll auch nur ein Beispiel sein, um ihnen zu zeigen, was möglich ist.
Z.ai bietet direkt im Browser einen vollwertigen Fullstack-Coder, powered by GLM-4.6. Anders als mein Tutorial-Projekt, ist das eine produktionsreife Lösung, die Sie sofort nutzen können.
Was macht den Z.ai Fullstack-Coder besonders?
Basierend auf meiner Recherche und Tests:
- Natural Language Programming: Beschreiben Sie was Sie wollen, der Agent baut es
- Intelligente Code-Completion: Context-aware Vorschläge über das gesamte Projekt
- Automatisches Debugging: Findet und fixt Fehler eigenständig
- Codebase Q&A: Stellen Sie Fragen zu Ihrem gesamten Code - das Modell versteht den Kontext
Z.ai's Web-Interface: Fullstack-Coding direkt im Browser mit GLM-4.6
Performance-Highlights:
- 55+ Tokens/Sekunde: Real-time Interaktion
- 200K Context Window: Versteht große Codebases komplett
- Vision Understanding: Analysiert Screenshots und UI-Mockups
- Web Search Integration: Recherchiert aktuelle Docs on-the-fly
Wann welche Lösung?
Seien wir ehrlich: Mein Swarm ist ein Learning Projekt. Und nicht mehr.
Aktuelle Cloud Lösungen von großen Anbietern sind deutlich überlegen:
- Frontend-fähig: Erstellt komplette UIs (was mein Swarm nicht kann)
- Task Management: Plant und organisiert eigenständig
- Professioneller Code: State-of-the-art Architektur, nicht nur "funktioniert irgendwie"
- Zero Setup: Direkt im Browser loslegen
Fullstack Engineer Cloud Agents:
- ✅ Für ALLES Produktive: Ernsthafte Projekte, echte Workflows
- ✅ Deutlich bessere Ergebnisse: Professioneller, schneller, zuverlässiger
- ✅ Frontend + Backend: Full-Stack, nicht nur Code-Generierung
Beispiel: Calculator-App Generierung
Ich habe den Z.ai Web Engineer getestet: "Bau eine iOS-Style Calculator App". ZUgegeben, keine besonders komplexe Aufgabe und hier auch ohne Backend Komponente. Aber sind wir mal ehrlich: der Calculator ist einer der ersten Apps, die so ziemlich jeder junge/neue Webdev baut, um seine Skills zu erweitern. So war es auch bei mir. Und das rumgefummele mit HTML, CSS und JS war damals schon sehr aufwendig. Umso beeindruckender finde ich, dass das schreiben dieser Zeilen länger dauert, als die Calculator App des Z.ai Agenten. Zack: 30 Sekunden später war sie fertig - mit UI, Logik, und professionellem Code:
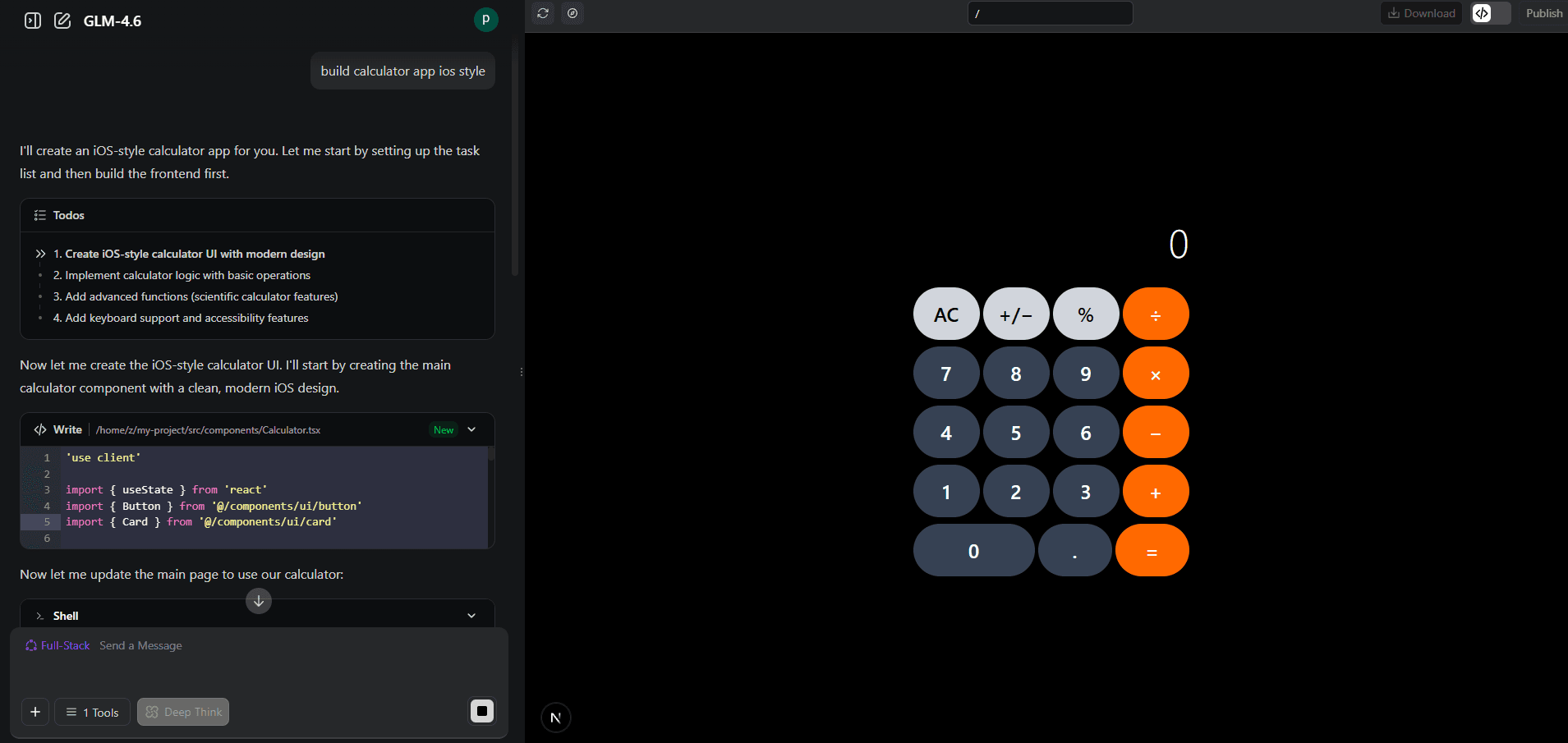
Der Z.ai Web Engineer baut in Sekunden Apps - mit Task-Management
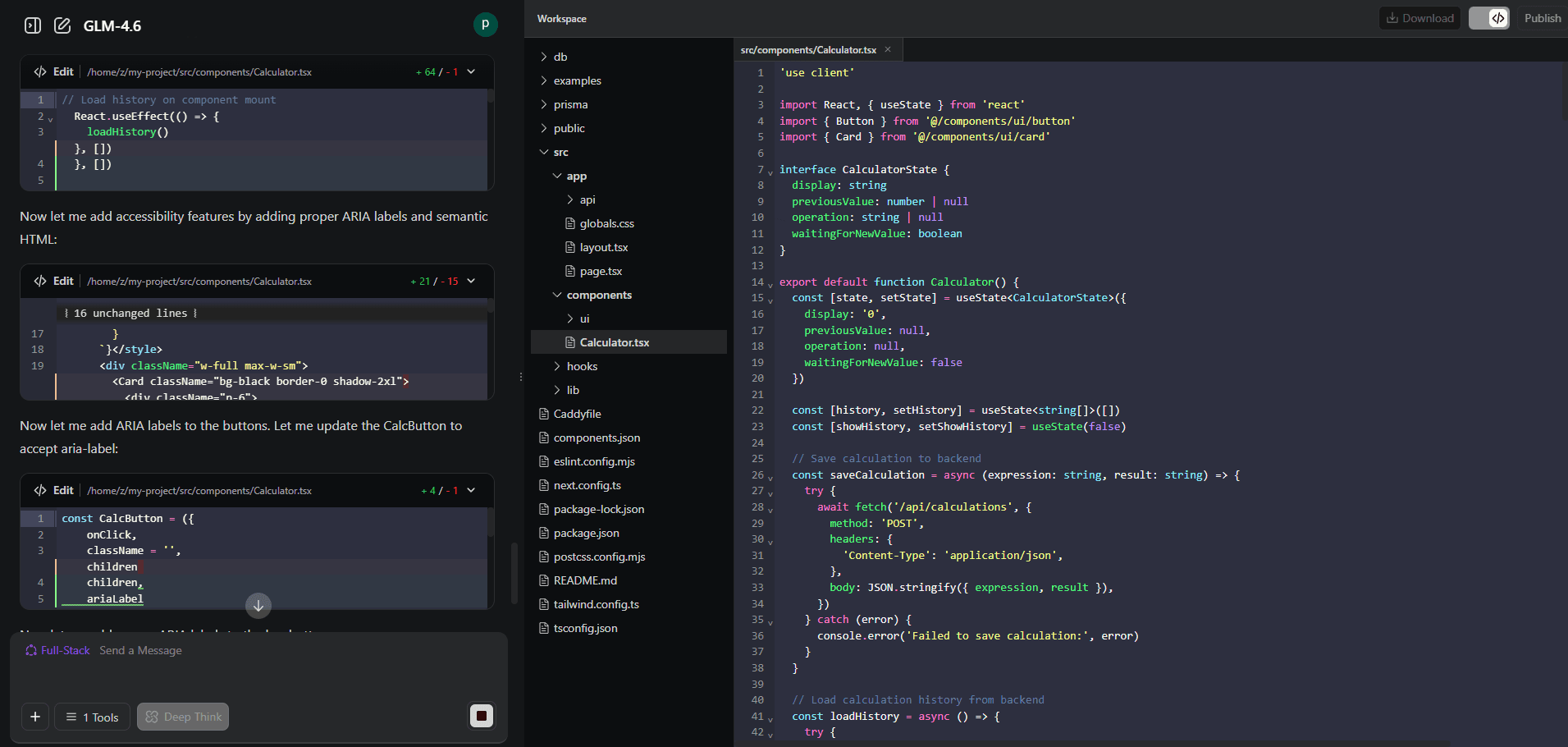
Sauberer, professioneller Code - so etwas kann mein Custom-Swarm nicht
Vergleich: Custom-Builds wie mein Swarm hier eignen sich für Lernzwecke und experimentelle Anwendungen. Für richtige Anwendungen sind ausgereifte Cloud-Lösungen technisch überlegen.
Matrix-Style Blog: Fullstack Agent in Aktion
Nach den ganzen Tests habe ich weiter experimentiert. Spaßeshalber habe ich dem Z.ai Fullstack Agent gesagt: "Bau mir einen Blog im Matrix Style / Terminal Style. In diesem Blog geht es um z.ai und wie der Fullstack Web Agent funktioniert."
Der verwendete Prompt war exakt:
Bau mir einen Blog im Matrix Style / Terminal Style.
In diesem Blog geht es um z.ai und wie der Fullstack Web Agent funktioniert.
Das Ergebnis ist sehr gut:
Der Z.ai Agent generiert in Echtzeit eine vollständige Next.js-Anwendung mit Matrix-Effekt
Was der Agent gebaut hat:
Ein vollständiges Next.js 15 Projekt mit:
- Matrix Regen Effekt - Canvas-basierter Hintergrund mit fallendem grünem Text
- Terminal Interface - Kommandozeile mit echten Befehlen (
help,clear,about,posts,matrix,read [id]) - Blog Posts über z.ai - Detaillierte Artikel über den Fullstack Agent, KI-gesteuerte Entwicklung, TypeScript und Next.js
- Interaktive Features - Klickbare Post-Cards, Terminal-Commands, Matrix-Informationen
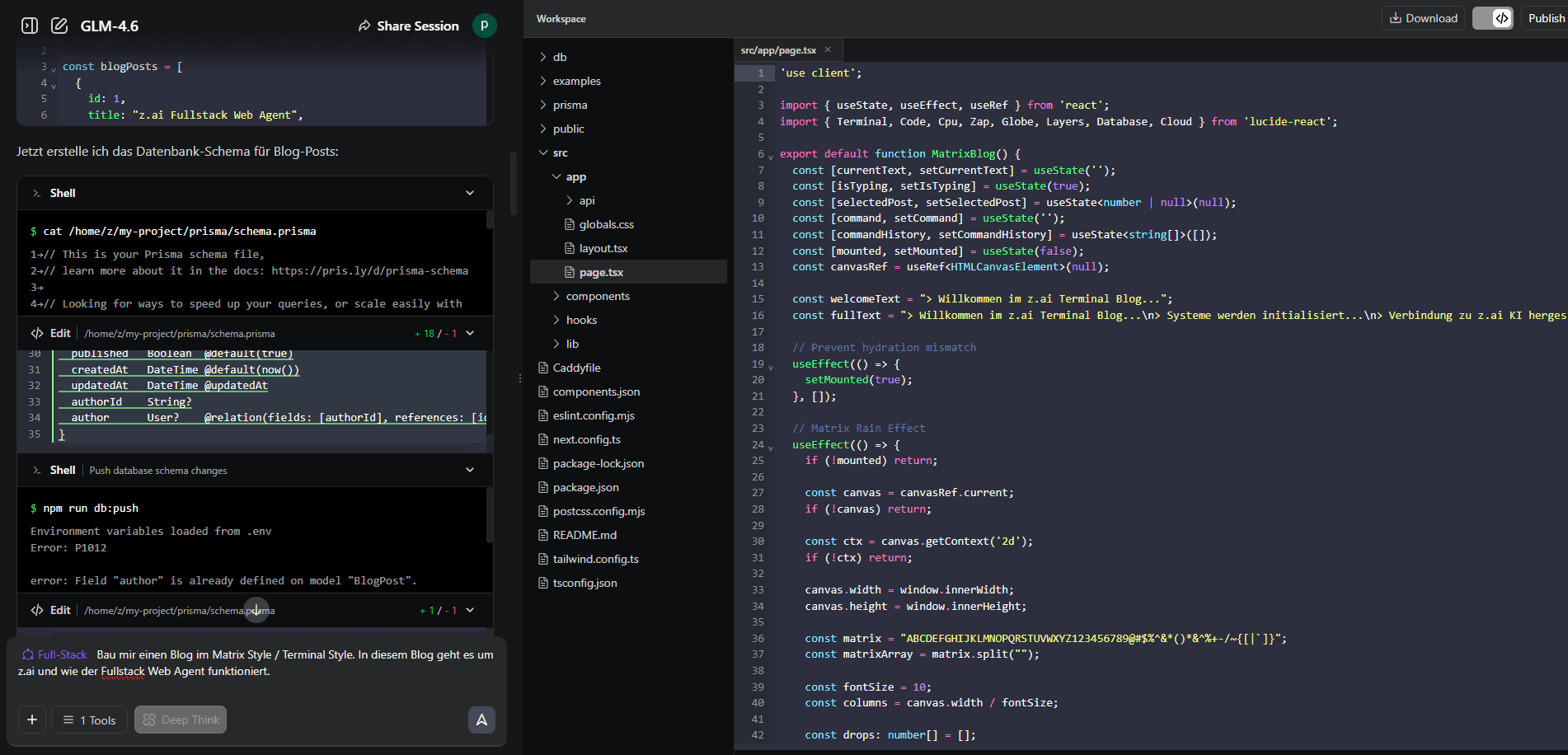
Das fertige Terminal-Interface mit funktionierenden Commands und Matrix-Effekt
Terminal-Befehle:
help- Zeigt verfügbare Befehleclear- Löscht das Terminalabout- Informationen über z.aiposts- Listet alle Blog-Postsmatrix- Matrix-Effekt Informationenread [id]- Liest einen bestimmten Post
Beispiel Code aus dem Projekt:
Der Agent hat sauberen, Code generiert - inklusive TypeScript, React Hooks, Canvas-Animation und responsive Design:
"use client";
import { useState, useEffect, useRef } from "react";
import { Terminal, Code, Cpu } from "lucide-react";
export default function MatrixBlog() {
const [currentText, setCurrentText] = useState("");
const [isTyping, setIsTyping] = useState(true);
const canvasRef = useRef<HTMLCanvasElement>(null);
// Matrix Rain Effect
useEffect(() => {
const canvas = canvasRef.current;
if (!canvas) return;
const ctx = canvas.getContext("2d");
if (!ctx) return;
// Matrix character set
const matrix = "ABCDEFGHIJKLMNOPQRSTUVWXYZ123456789@#$%^&*";
const fontSize = 10;
const columns = canvas.width / fontSize;
const drops: number[] = [];
for (let x = 0; x < columns; x++) {
drops[x] = 1;
}
const draw = () => {
ctx.fillStyle = "rgba(0, 0, 0, 0.04)";
ctx.fillRect(0, 0, canvas.width, canvas.height);
ctx.fillStyle = "#0F0";
ctx.font = fontSize + "px monospace";
for (let i = 0; i < drops.length; i++) {
const text = matrix[Math.floor(Math.random() * matrix.length)];
ctx.fillText(text, i * fontSize, drops[i] * fontSize);
if (drops[i] * fontSize > canvas.height && Math.random() > 0.975) {
drops[i] = 0;
}
drops[i]++;
}
};
const interval = setInterval(draw, 35);
return () => clearInterval(interval);
}, []);
// ... rest of component
}
Generierte Projektarchitektur
Der Z.ai Fullstack Agent hat nicht nur den Code geschrieben, sondern auch eine umfassende Architektur-Dokumentation erstellt. Hier ist ein Screenshot aus dem Chat, wie der Agent die Mermaid-Diagramme generiert hat:
Der Z.ai Fullstack Agent generiert automatisch Architektur-Diagramme im Mermaid-Format
Die folgenden Diagramme zeigen die vollständige Architektur des generierten Terminal-Blog-Projekts:
Vollständige Projektarchitektur

Gateway Layer (Caddy), Next.js Application Layer, Data Layer (Prisma + SQLite), UI Components (shadcn/ui), State Management (Zustand + TanStack), AI Integration (z-ai-web-dev-sdk)
Data Flow Architecture

Client-Side Flow → Next.js Runtime Processing → Data Processing Layer → Storage Layer → External Services (z.ai APIs)
Component Hierarchy

Layout Layer → Page Layer → Feature Components (Matrix Rain, Terminal, Blog Grid) → UI Components → Hooks & Utils
Technology Stack Overview

Next.js 15, React 19, TypeScript 5, Tailwind CSS 4, shadcn/ui, Prisma, SQLite, Zustand, TanStack Query
Security & Performance Architecture

Security Layer (HTTPS, CORS, CSRF, XSS) → Authentication & Authorization → Data Validation → Performance Optimization → Monitoring & Analytics
Key Architecture Features
- Modular Design - Klare Trennung der Verantwortlichkeiten
- Type Safety - Durchgehend TypeScript mit Zod-Validierung
- Performance - Optimiert mit Caching, Lazy Loading, Bundle Optimization
- Security - Umfassende Sicherheitsmaßnahmen
- Scalability - Flexible Architektur für zukünftiges Wachstum
- AI Integration - Nahtlose Integration mit z.ai Services
Wichtiger Hinweis zur Sicherheit:
Auch wenn das Ergebnis beeindruckend ist, solltet ihr aufpassen bei sicherheitsrelevanten Features. Lasst immer einen Experten draufschauen, wenn ihr mit sensitiven Daten arbeitet oder Admin-Routen oder ähnliches schreibt. Auch ein extrem gutes Modell wie GLM-4.6 kann Fehler machen - besonders bei Security-kritischen Implementierungen.
Mehr Infos:
Weiterführende Ressourcen
Wenn Sie tiefer einsteigen wollen:
- LangGraph Cookbook: Fortgeschrittene Patterns und Beispiele → langchain-ai.github.io/langgraph/tutorials
- Z.ai Advanced Features: Erkunden Sie Function Calling, JSON Mode und Vision → docs.z.ai/guides
- Community: Tauschen Sie sich mit anderen Entwicklern aus → Z.ai Discord
- GitHub Repository: Github → github.com/jovicdev97
Ressourcen: